開放政治獻金 - OCR技術討論
給最終使用者的人工 OCR/校對網站在這邊討論
圖檔格式
縮印?
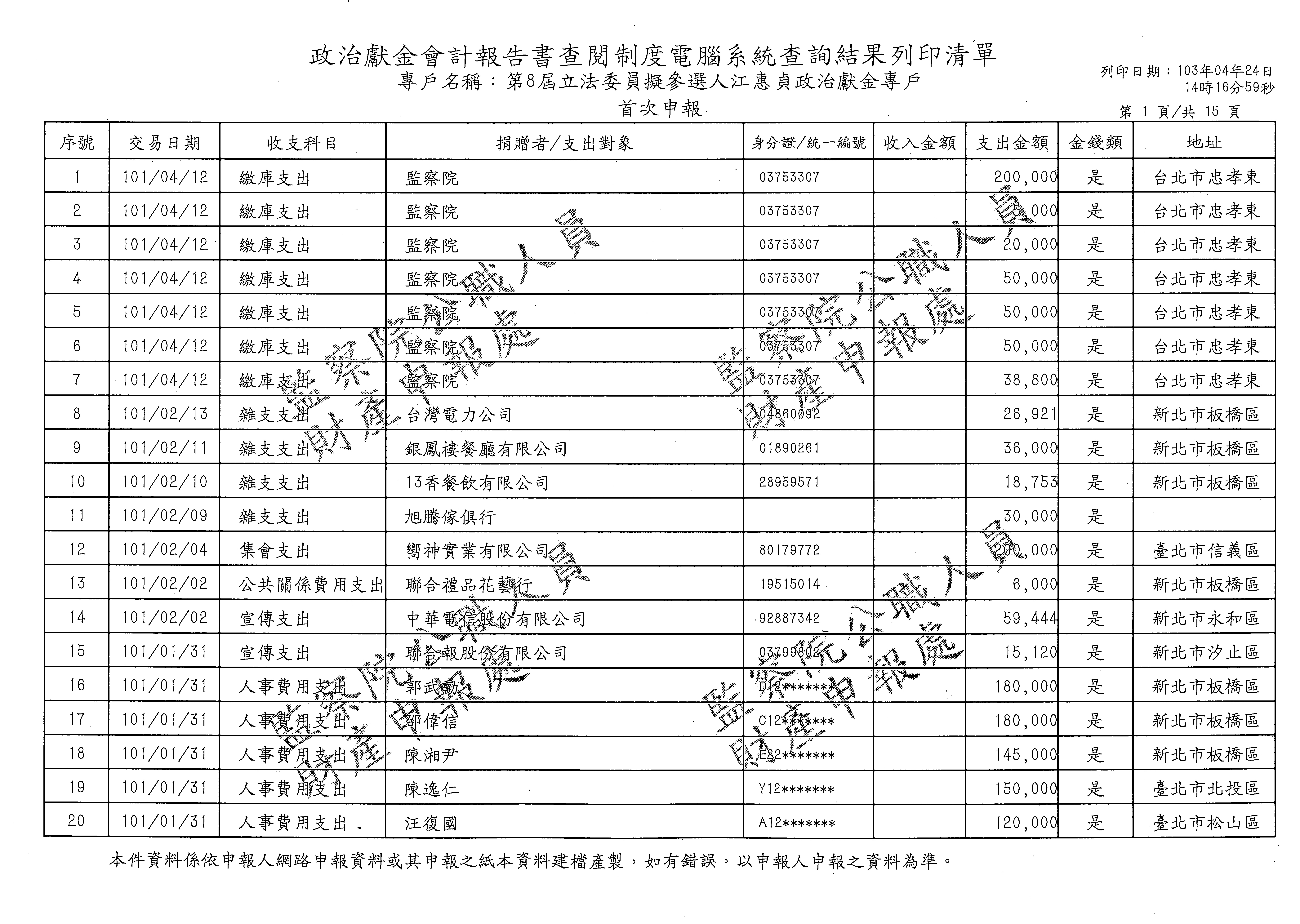
浮水印處理
- 目前掃描的結果至少有三種比較不一樣的 pattern
- http://pic.pimg.tw/ronnywang/1398355833-3935933860.jpg 字比較粗,浮水印的點比較小
- http://pic.pimg.tw/ronnywang/1398356068-3799096785.jpg 字比較細,浮水印的點比較大
- http://pic.pimg.tw/ronnywang/1398270666-705020037.png
- 後勤中心 Shenk Wang 建議 使用 http://scantailor.org/ 進行前置處理,可以補強 ClearScan 無法處理浮水印的問題,值得一試!
- Note: 我測試的參數是
- --layout=1 \\
- --margins-left=10 \\
- --margins-right=10 \\
- --margins-top=5 \\
- --margins-bottom=5 \\
- --color-mode=black_and_white \\
- --threshold=-50 \\
- --despeckle=aggressive \\
- *.png out
- 浮水印我之前是透過 image magick 處理,透過下面這樣的指令可以有不錯的效果
- convert {$file_orig} -morphology thicken ’1x3>:1,0,1’ {$file_target}
-
- 利用表格左上右上兩點找出浮水印的位置再強力清除處理那附近的雜點不曉得可行性多高
- 範例圖: https://www.dropbox.com/s/yam9ykpcjl1kznm/sample.png
- 試著寫了一下,目前只要給我表格最上面那條線的兩點座標就可以把浮水印的區塊拿出來特別處理,見:
- https://github.com/shenkyw/tw-campaign-finance/commit/070de4d3d372375c7454eb3e86019f4b1ca0cdf6
欄位、格式分析
- Ronny Wang 分享如何抓出掃描文件的每個欄位
- 切框線確認(demo 網頁:速覽每份表格欄位切得如何)
- 從圖檔抓出欄位資訊,所有程式碼和資料在 github (以上 Ronny Wang ++)
- "發現 tesseract 的 hocr config 可以抓出有字的 bbox: tesseract foo.png out/foo hocr -- 輸出是 html tag. 姑且不論辨識是否正確,拿到 bbox 後至少可以切出來做人工ocr" from gugod1 @ irc
以現有工具自動 OCR
- 將 PDF 轉為 ClearScan,並做第一階段的機器識別 -au
- 參考範例檔 ,其中文字已可剪下貼上
- 已經上載 ClearScan + OCR 結果: https://drive.google.com/folderview?id=0B9tD1zENsweyUmZycEhWZjR5MUk&usp=sharing
- 目前只識別沒有疊到浮水印的欄位,如果能移除浮水印則更佳
- https://github.com/yllan/TextPositionExtractor
- 接著就是要以這個結果去處理文字排版,然後找出欄位對應關係,接著就是人工 captcha 了
- 已經將 Ronny 與 yllan 的成果合併到
- https://github.com/kiang/tw-campaign-finance
- 展示頁面可以參考
- http://kiang.github.io/tw-campaign-finance/demo_text.html
使用 tesseract 辨識
參考 sample code: https://github.com/hialan/php-strip-watermark/blob/master/php/batch_tesseract.php- 英文數字辨識較佳
- 中文偶爾會成功
- 測試結果,目前每個豆腐高 50 px ,中文辨識率較佳
- 辨識訓練工具 - http://vietocr.sourceforge.net/training.html
- 可以藉由這個工具去產生比較好的 OCR 資料庫,這樣一來就可以提昇辨識結果
- 各種外掛 - https://code.google.com/p/tesseract-ocr/wiki/AddOns
https://github.com/buganini/ocrap
以行為單位半自動的辨識,需要人工介入,接網站API的部份待實作,但網站上看起來有些(舊?)資料似乎沒有deskew,表格沒切好,遇到這種狀況miss rate會很高
整合開發
- polor1010
- 圖檔做文字的擷取,包含過濾浮水印,和文字定位(目前只能定位數字)
- https://www.dropbox.com/s/0dlkiyik1s6ypqb/WordExtract.zip (處理結果 )
- 有些定位結果不準確,研判是斷掉的元素connect component無法連接。小弟正著手加強這部分。
- Ex: 顏清標_雜支支出_雜支支出_0\\cell7_1_R, cell13_1_R, cell1_4_R, cell2_1_R
- https://www.dropbox.com/s/xthh56gqpzda2nu/recognition%20results.zip (辨識結果)
- 數字辨識結果更新至政治獻金伺服器
- 新增 command mode, 辨識結果 json 格式輸出
- https://www.dropbox.com/s/33q9qnjnwbt1loj/test.zip (test檔案和辨識結果)
- 程式碼請參照 https://github.com/polor1010/tw-campaign-finance-recogntion
- 中文字定位 (未完成)
其他
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}